6 Intro to ggplot2
“The greatest value of a picture is when it forces us to notice what we never expected to see.”
— John Tukey
“There is no single statistical tool that is as powerful as a well‐chosen graph.” (Chambers et al. 1983)
Why Do We Care About Visualizing Our Data?
Consider the following scenario:
There are two different datasets, each comprised of individuals measured on two outcomes (say height and weight). The mean and standard deviation of height and of weight are the same in both datasets. The correlation between height and weight is the same in both datasets as well. By every statistical metric, these datasets are the same. So, they must look similar, right?
Click the button below:
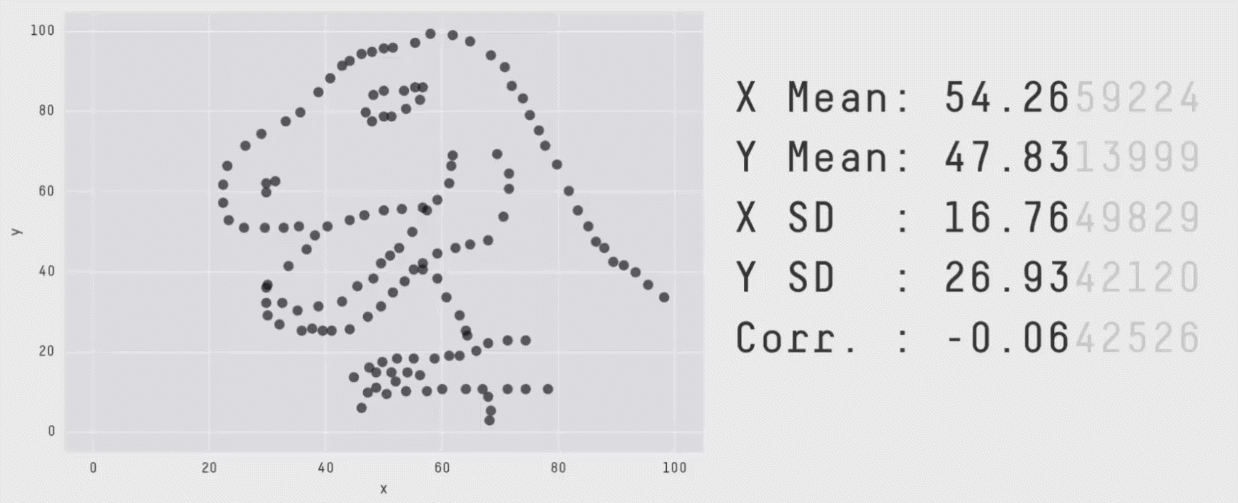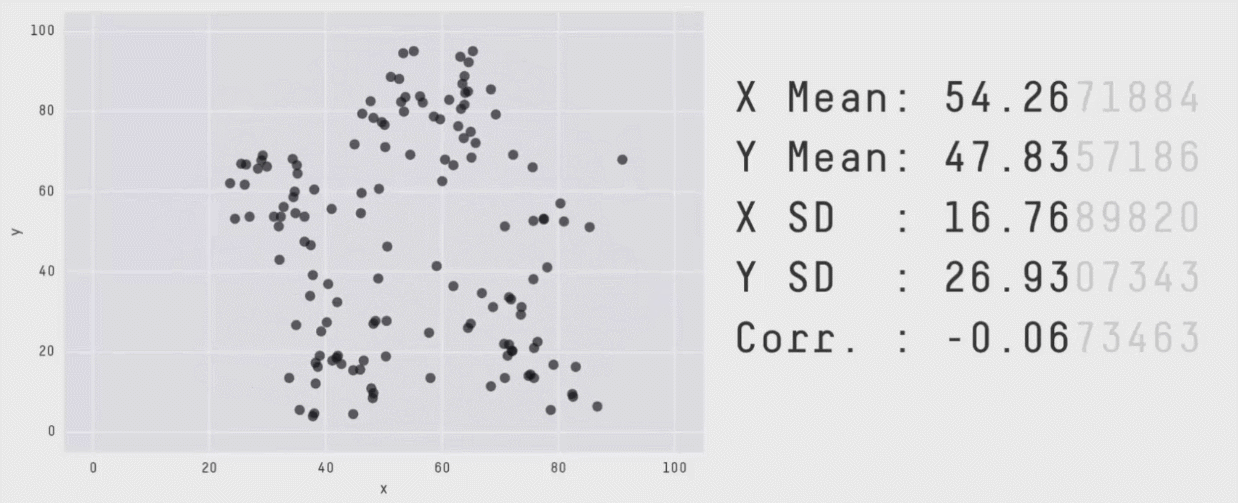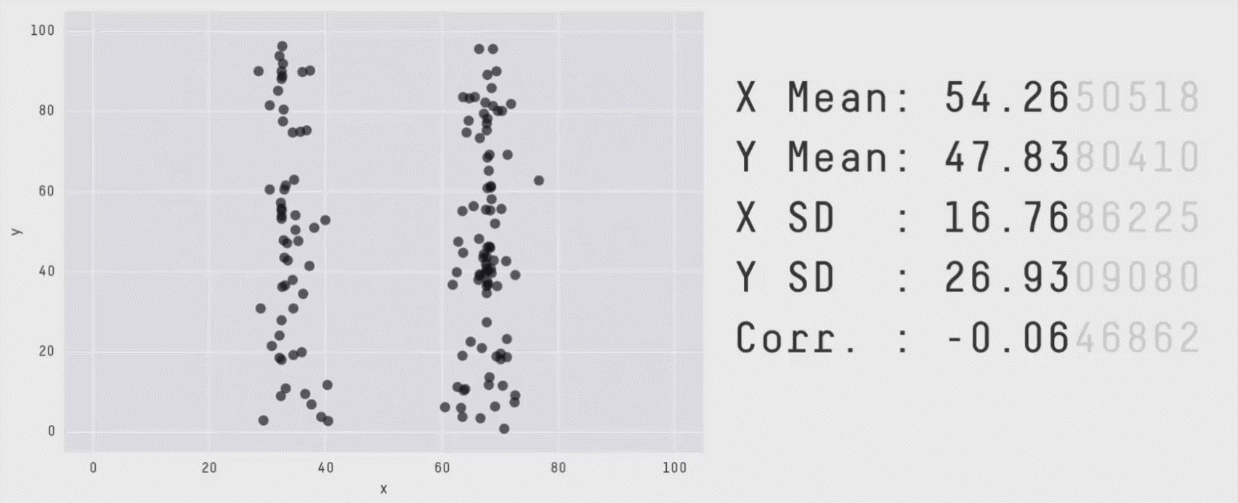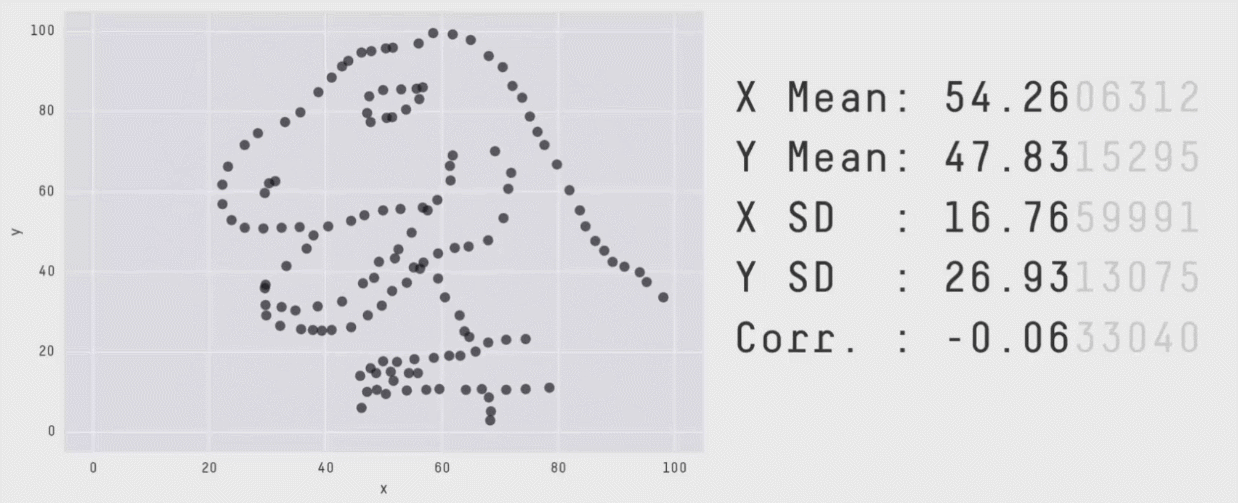

This collection of data is called the datasauRus, and more information about how these were generated can be found in this technical paper. This is a modern version of the famous Anscombe’s Quartet:
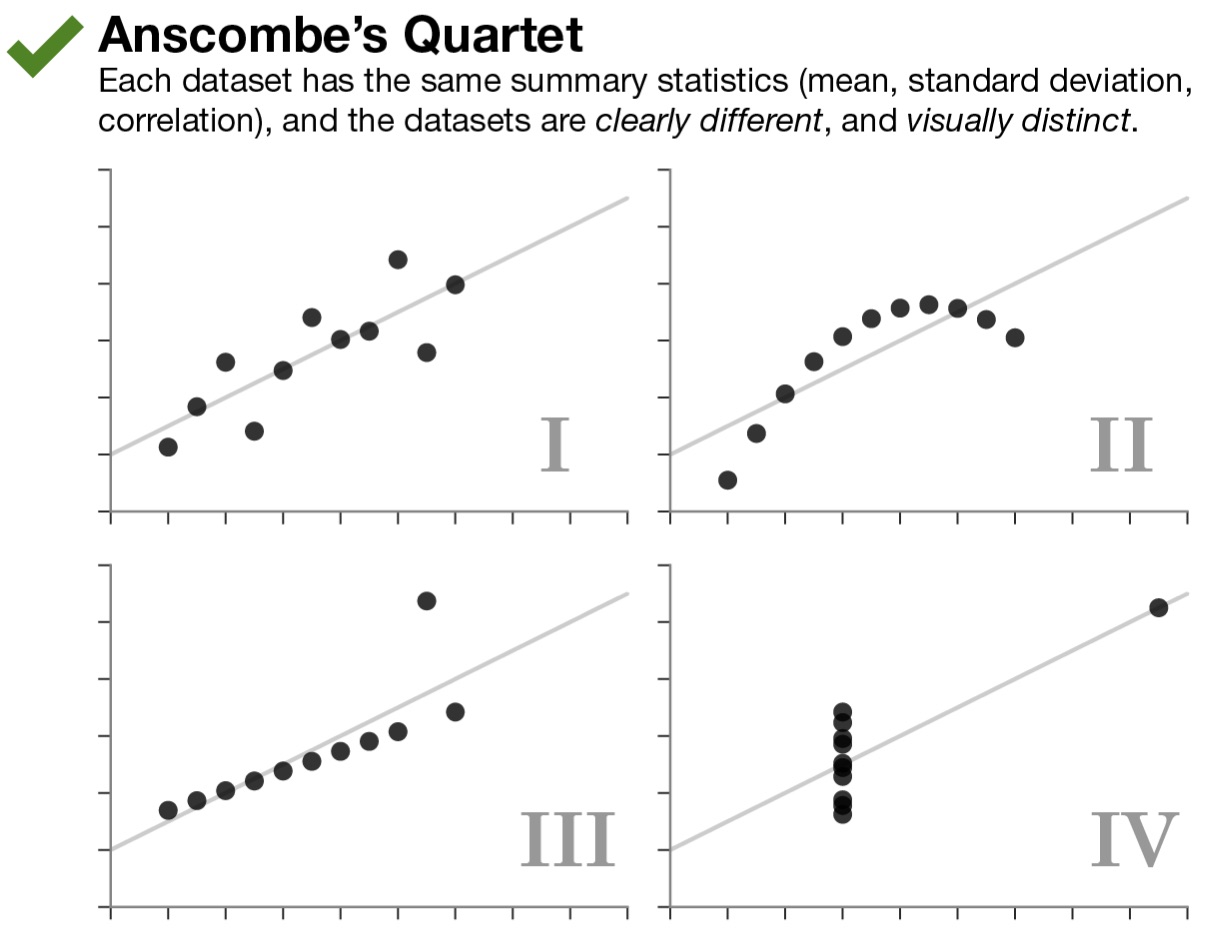
All four of these datasets have matching sample sizes (n’s), means, standard deviations, and correlations. This means that the slope and intercept, and corresponding statistical tests, will all be equivalent. The data clearly look different though. (These data are built into R in an object called anscombe, which you can look at to test this for yourself!)
The key point here is that the summary statistics of some variables and their linear relationships inherently overlook some aspects of the data. This highlights the critical importance of visualizing your data, and not just relying on summary statistics alone. The point of a visualization, just like a summary statistic, is to understand a relationship or pattern in your data. However, by looking at the raw data itself with a visualization, you do not run the risk of missing things the way you do by relying on summary statistics alone.
6.1 When Visualizing Go Wrong
It is easy enough to just say, “Look at your raw data! Create a visualization!” However, a bad visualization is often times worse than no visualization at all. One of the things that the Covid-19 pandemic brought with it originally was a plethora of data visualizations. Below are a few that were observed out in the real world between 2020 and 2021. Try to think about why these are weird/problematic.
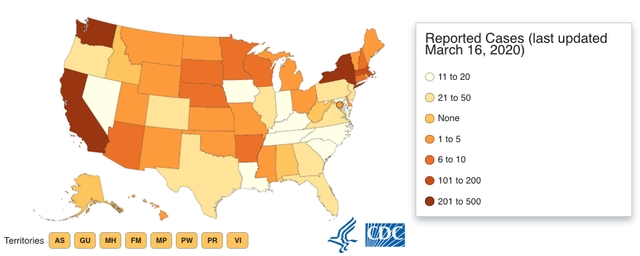
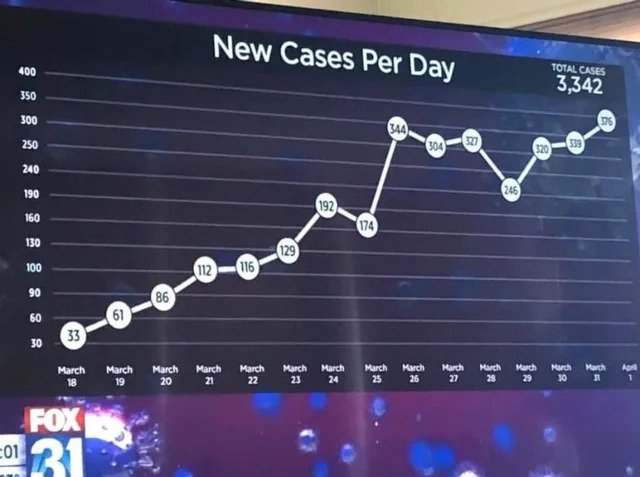
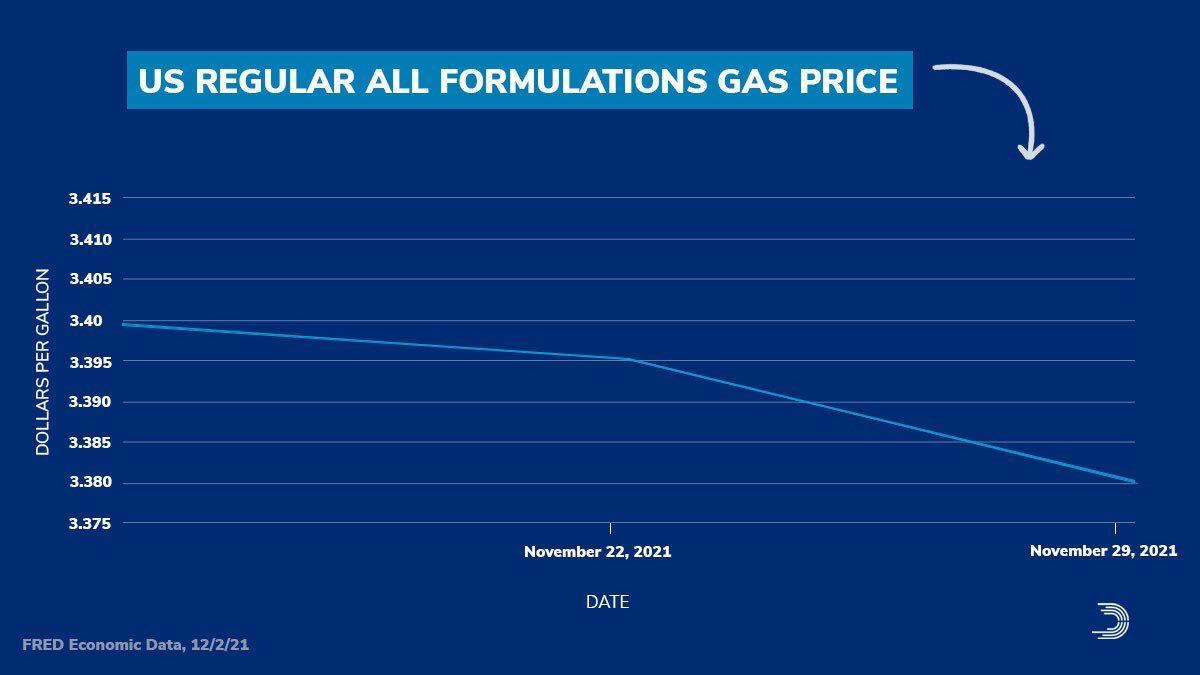
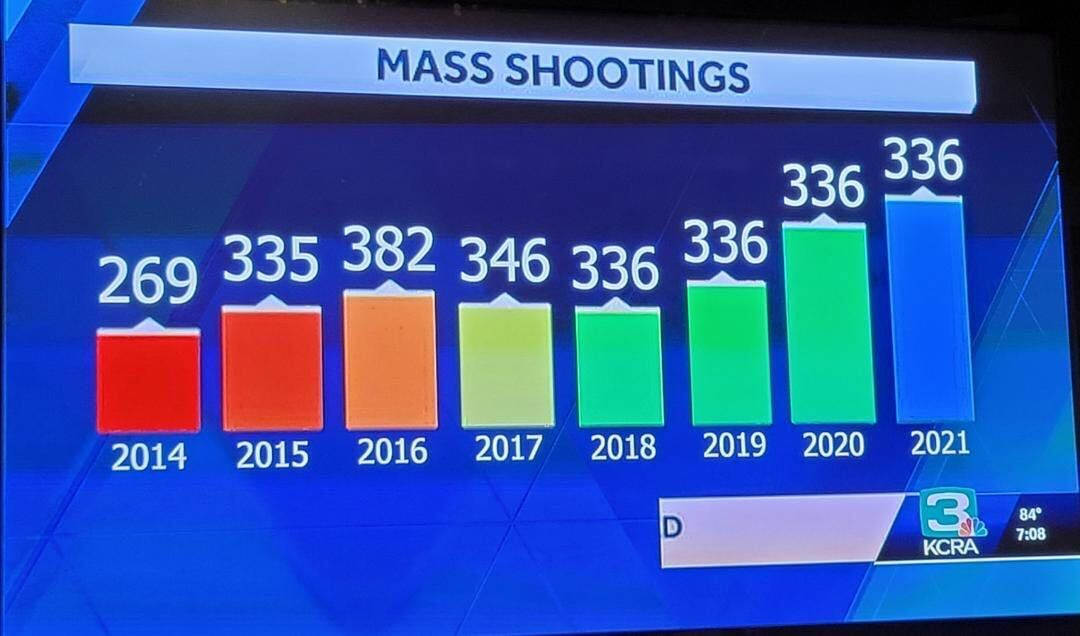
So, it is not enough to just make some visualization, it is important to also consider the principles that make a GOOD visualization. Over the next few lessons, both will be covered.
6.2 ggplot2
While some may argue otherwise, data visualization is one of the things that sets R apart from other programming languages that can be used for statistics (e.g., Python). R still has the best data visualization capabilities. This is also one of the first times you will get to see what coding can be all about. You are actually going to be creating some tangible output with your code!
In this class, the ggplot2 package will be used to create visualizations (e.g., graphs). Graphs are constructed by mapping data to geometric objects (lines, bars, points, etc.) according to some aesthetic attributes (color, shape, size, etc.). ggplot2 uses this to inform its grammar.

Artwork by Horst (2022)
6.2.1 Meet the Penguins
To create visualizations, you need some data to visualize! The palmerpenguins dataset from Alison Horst will be used to create examples throughout.
This dataset contains measurements from 344 different penguins. Measurements include things like bill length and depth, sex, among others.
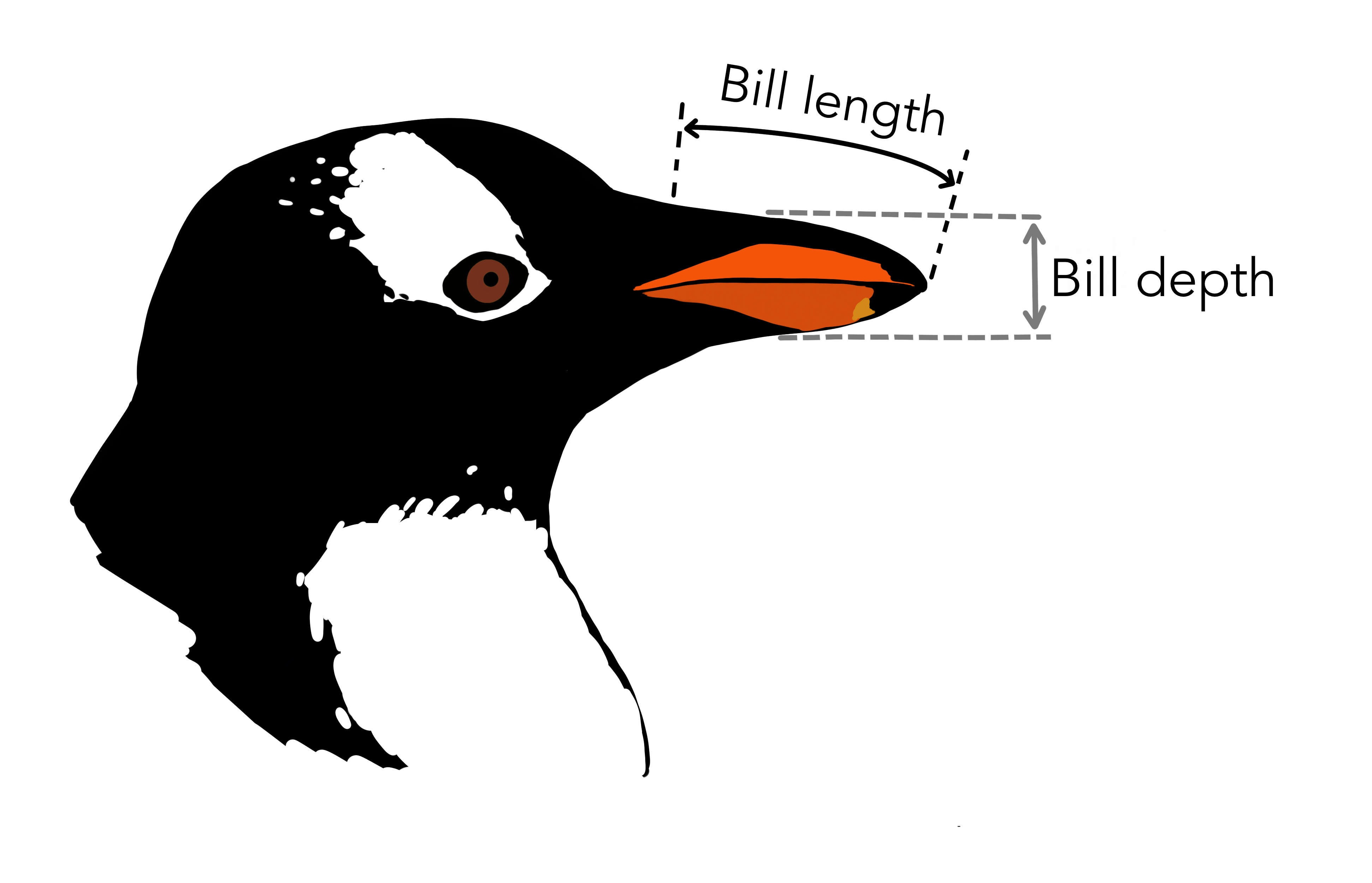
Artwork by Horst (2022)
There are 3 different species of penguins in this dataset, collected from 3 islands in the Palmer Archipelago, Antarctica.

Artwork by Horst (2022)
Use the library(palmerpenguins) call to load in the dataset.
6.3 A Basic Graph
The most sensible place to start is building a basic graph. There are going to be LOTS of exercise breaks throughout.
Note: As you move forward with building your first graph, each new piece of code added will be accompanied by a literate programming portion, where you will describe in words what the code is doing.
All ggplot graphs are build using the ggplot() call. The first thing it needs is some data. The %>% will be used to pass in the penguins dataframe.

Start by telling ggplot to use the
penguinsdataframe for the data
Woo! This actually created something. A grey rectangle! Of course, the code above alone will not do anything. You have to tell ggplot what you want to plot. Hmm… As an example, consider how a penguin’s bill_length_mm is related to its flipper_length_mm. You might imagine that bigger penguins would tend to have longer bills and flippers, but maybe not? That is why you create visualizations, to try and help answer questions you may have about your data (which consist of samples thought to be representative of the world at large)!
ggplot needs to be told what variables from your data should be mapped to the aesthetics you want to render on your graph. You will do that with the aes() call, and start with specifying what to display on each axis.
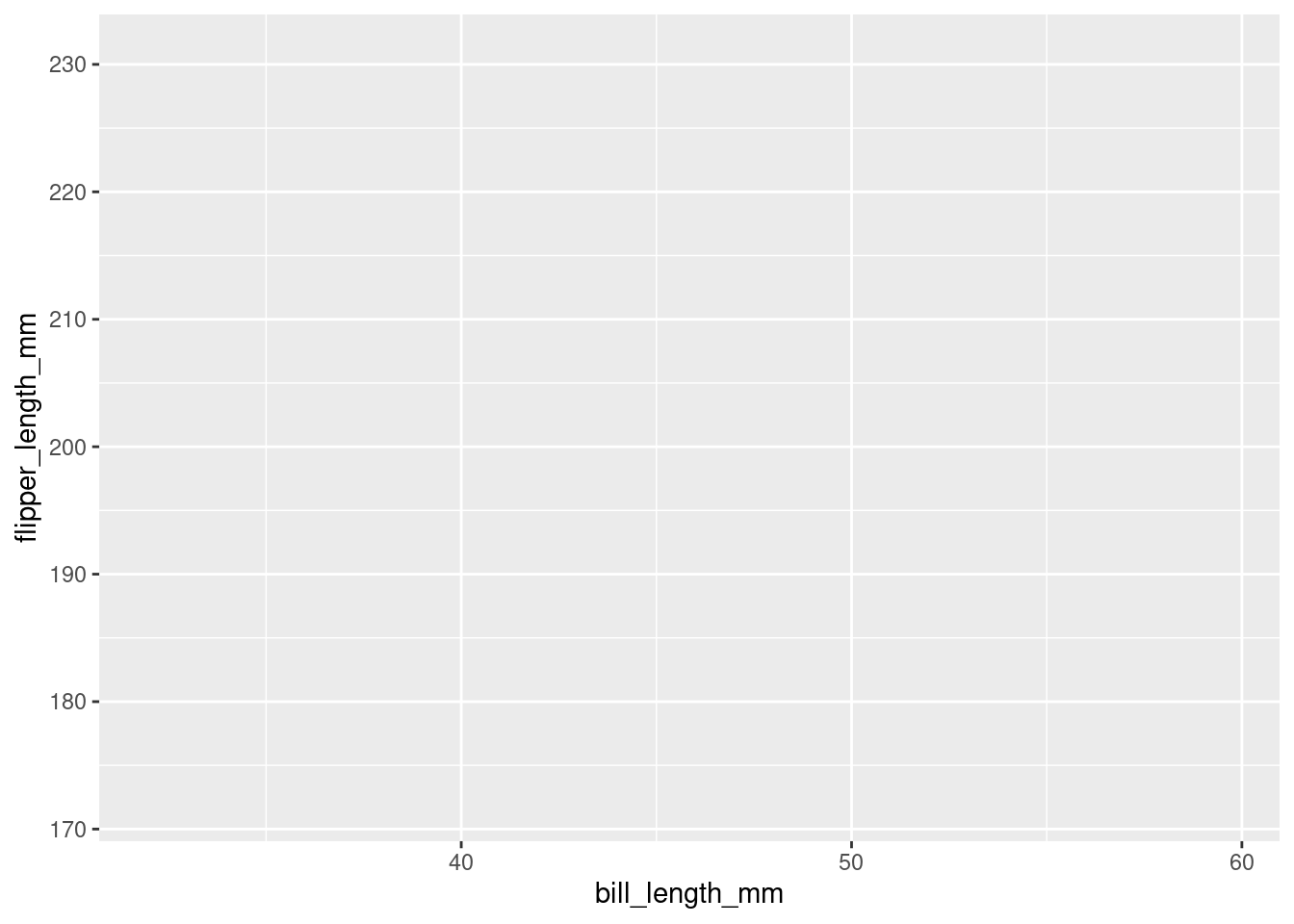
“Start by telling ggplot to use the
penguinsdataframe for the data, map flipper length to the y-axis and bill length to the x-axis.”
Above, it was specified that flipper_length_mm should be on the y-axis, and bill_length_mm on the x-axis (it is good practice to specify y first and x second). All aesthetic mappings must be separated by a comma, and it does not matter the order you list them (though it is good practice to start with the axes first). As you can see, ggplot figured out how to label the axes on its own.
ggplot was told what the aesthetic mappings are (what data source to use), but not what it should render from those mappings! You want ggplot to use those mappings to construct some geometric object, and the way you do that is by adding a geom, aptly named. There are a number of different geoms, which have the general syntax of geom_X(), where X usually refers to the specific geometric object you want to render. Here, you want a point on the graph for each penguin, so geom_point() will be used.
Note: There are a TON of different geoms. You will see many more later.
penguins %>%
ggplot(mapping = aes(y = flipper_length_mm,
x = bill_length_mm)) +
geom_point()
#> Warning: Removed 2 rows containing missing values
#> (`geom_point()`).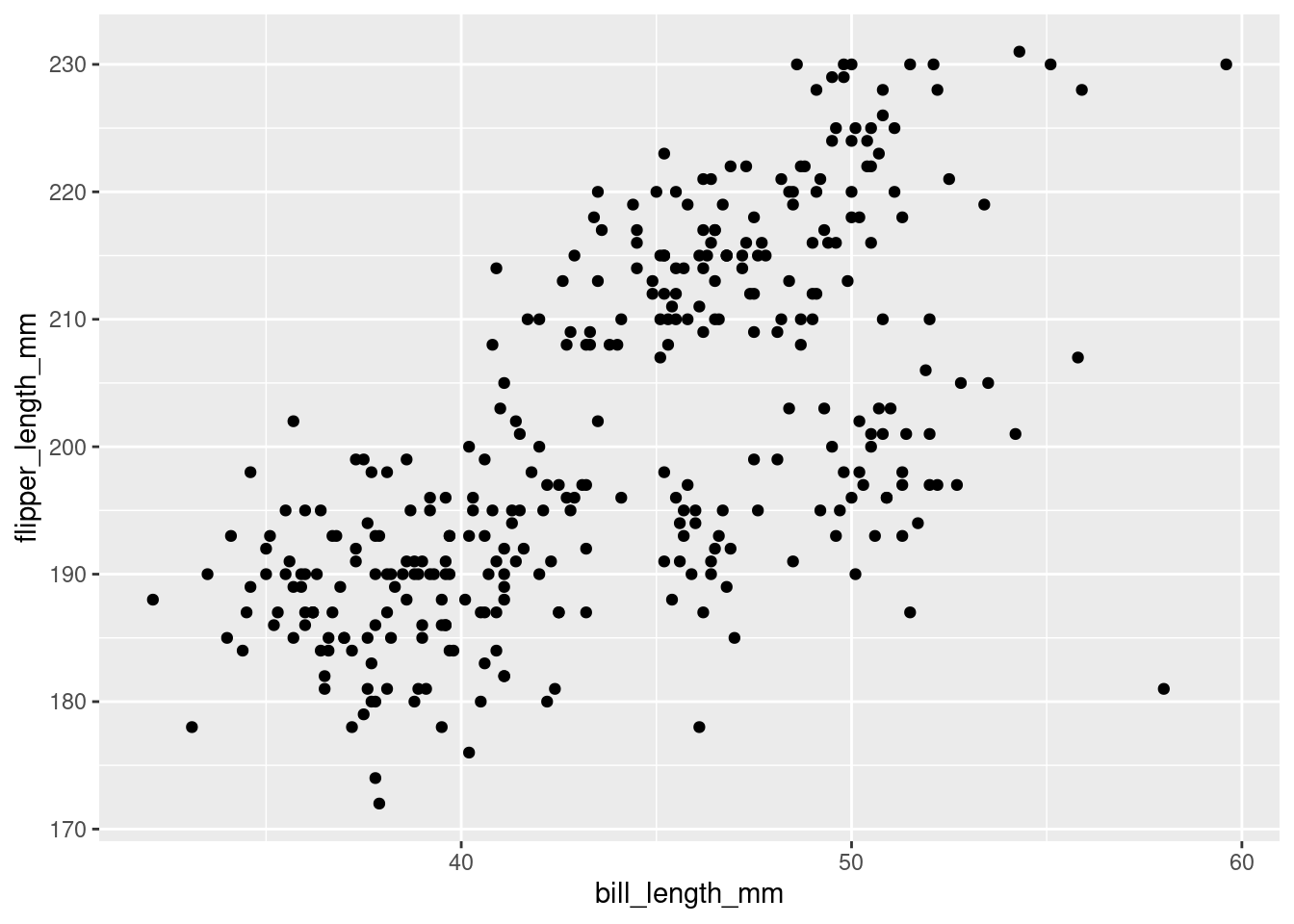
“Start by telling ggplot to use the
penguinsdataframe for the data, map flipper length to the y-axis and bill length to the x-axis. Represent each observation with a point.”
Okay, NOW we are talking! This looks like an actual real graph. Look at your very first ggplot masterpiece!
There are two important things to note here:
The
+was used instead of%>%to add on a new function. The ggplot system is additive/layered, which is a very powerful idea that will be explained later. For now, it is enough to know that thegeom_point()was being added to the code. You do not want to take thepenguins %>% ggplot(mapping = aes(y = flipper_length_mm, x = bill_length_mm))code and use it as the argument for thegeom_point()function, which is what would happen if a%>%was used to pipe it! You want to just add the points on top of the existing base that code created, which is why the+is used.When running this code, in addition to creating the graph (in the “Plots” section of RStudio or inline under your code), the following showed up in the console:
Warning message:
Removed 2 rows containing missing values (geom_point).
Looking at your warnings and errors is always important, but especially so when creating visualizations! This says that it removed 2 rows of data. That may not seem like a big deal but you do not want your visualizations to be misleading, especially when you start visualizing summary statistics (like means). If you look at your actual data though, you can verify that there are two penguins that do not have a measurement value for flipper length or bill length. So obviously without either or both of those, it cannot be included on the graph. In this case, this is okay, but it is important to always verify!
NOTE: moving forward, for pedagogical purposes this warning message will be hidden so the output from subsequent code is cleaner. However, those 2 rows are still being removed!
Above, it was noted that the goal of a visualization is to understand a relationship, or pattern, in your data. For every visualization you make, a verbal description of the pattern seen (should one exist!) will be provided underneath. This will help develop an intuitive graph literacy. Being able to quickly and accurately interpret visualizations is an important skill, and one of the pillars of this course.
Things related to graph literacy and comprehension will appear in boxes like this moving forward!
In the visualization it can be seen that, generally speaking, penguins with greater flipper length tend to have greater bill length as well. There seems to be a positive linear relationship between bill length and flipper length such that, as flipper length increases, bill length increases in turn.
Note: You have to use a lot of tentative language and include many qualifiers here. No formal statistical analyses have been done to afford the ability to state any relationship or effect definitively.
6.4 References:
Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/
Shannon Ellis for the “coding out loud” idea for ggplot code.